2019.07.30
출처 : http://cs231n.stanford.edu/slides/2018/cs231n_2018_lecture10.pdf
핵심키워드
- RNN
- Gradient Clipping
RNN
기존에 RNN에 대해서 이론적으로, 그리고 간단한 실습을 통해 알아봤지만 누군가에게 설명할 수준은 못됐다. 따라서 모두를 위한 딥러닝에 있는 RNN 강의 자료와 cs231n의 자료를 참고하여 기존 RNN 개념의 보완 관점에서 글을 포스팅하고자 한다.

RNN의 기본구조는 hidden state의 값을 old state와 해당 time step의 input vector를 이용해 계산한다. 주로 activation function으로 하이퍼볼릭탄젠트 함수를 사용한다. 그 이유는 backpropagation에서의 이점 때문이다.

그리고 모든 time step에서 동일한 function과 parameters의 set을 사용하고, 모든 time step이 끝난 후, loss를 계산하여 backpropagation으로 gradient를 계산하는 구조로 흘러간다.

Character-level에서의 Language Model을 RNN으로 학습하는 구조다. “hello”라는 sentence를 문자 단위로 token화한 뒤, one-hot vector로 인코딩해서 input 준비를 한다. hidden layer에서는 input data(characters)와 직전 time step의 hidden state를 통하여 해당 time step(now)의 hidden state를 계산하여 다음 time step으로 전달한다. 그리고 해당 time step에서 output 값의 softmax값과 target 값을 비교하여 loss를 계산하여 다시 training하는 구조를 가진다.

모든 sequence가 끝나면 loss 계산을 위해, 모든 sequence에서 gradient를 계산한다.

모든 sequence에서 계산하지 않고 일부 time step 범위에서만 gradient를 계산하는 기법도 있다.
그렇다면 gradient를 계산하는 flow를 알아보자.
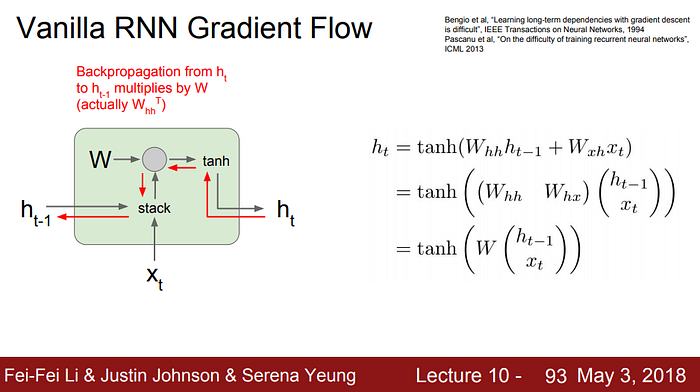
기본적인 Vanilla RNN의 경우 hₜ에서 직전 hidden state까지의 backpropagation은 위와 같다.
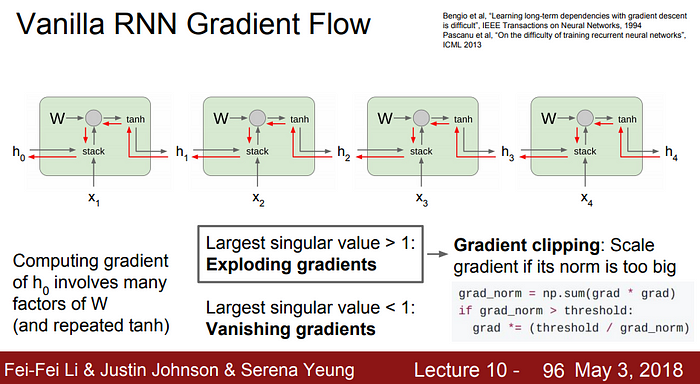
하지만 전체적인 구조에서 볼 때, gradient를 계속 곱해가는 과정이므로, singular value의 가장 큰 값이 1이 넘는다면, gradient가 발산하는 양상이 되고, singular value의 가장 큰 값이 1보다 작다면, gradient가 사라지는 문제가 생긴다.
따라서, Largest singular value가 1보다 크다면, Gradient clipping을, 1보다 작다면, RNN architecture에 변화를 준다.
- Gradient Clipping
깊은 뉴럴넷에서 Gradient가 발산하는 것을 방지하는 기법이다. 다양한 방법이 있지만 주로, gradient의 L2 norm이 기준 값을 초과할 때, threshold / L2 norm을 곱해준다. 결과적으로 gradient의 norm이 threshold를 넘지 않도록 유지해준다. 기존의 SGD가 아닌 Adam Optimizer를 사용한다면, 굳이 Gradient Clipping을 사용하지 않아도 되지만, 안전장치로 사용하는 것은 괜찮다.
자세한 내용 : https://kh-kim.gitbook.io/natural-language-processing-with-pytorch/00-cover-6/05-gradient-clipping
