2020.01.20
Reference
Abstract
먼저, 해당 논문은 Non-recurrent sequence to sequence encoder-decoder model을 만드는 것이 목표이다.
Background
1. Sequential computation
sequence to sequence한 문제를 푸는 과정에서, Encoder-Decoder 구조의 RNN 모델들이 좋은 성능을 냈다.
2. Long term dependency
RNN의 경우, Long term dependency의 문제가 항상 따라다니고, CNN의 경우 kernel 안에서 O(1)이나, kernel 간 정보가 공유되지 않는다.
Model Architecture
Encoder
인코더의 경우는, 논문에서 6개의 stack으로 구성되어 있다고 했다. 하나의 인코더는 Self-Attention Layer와 Feed Forward Neural Network로 이루어져있다. (2개의 Sub-layer)
인코더 내부구조는 위와 같다.
인코더의 Self-Attention Layer를 살펴보면,
예시로, “Thinking Machines”라는 문장의 입력을 받았을 때, x는 해당 단어의 임베딩 벡터다.(512차원) Query, Key 벡터는 각각 dₖ = 64 차원으로 동일하다.
핑퐁블로그의 transformer 설명을 보면
- Query(Q) : 영향을 받는 단어 A를 나타내는 변수입니다.
- Key(K) : 영향을 주는 단어 B를 나타내는 변수입니다.
- Value(V) : 그 영향에 대한 가중치를 나타냅니다.
라고 정의했는데, Query 벡터 자체가 Key 벡터들과 Dot-Product되는 것이 영향을 받는 단어와 주는 단어들의 유사도를 측정하는 행위라고 이해했다.

Dot-Product Attention은 위와 같이 정의할 수 있다. 이것을 전체적으로 진행한 모습은 다음과 같다.
마지막에 value-vector와 곱해진 것을 z-vector로 표현했다.
실제 학습 시에는, 벡터 각각을 분해해서 위와 같이 곱하는 것이 아니라, 행렬 연산을 통해 위의 계산을 한꺼번에 한다.(아래)
지금까지 Encoder의 구조와 Self-Attention 방법에 대해 알아본 것이다.
Multi-Head Attention
논문에서는 self-attention layer를 다중으로 구현한 Multi-head attention을 제시했다. multi-head attention은 self-attn 보다 두 가지 측면에서 더 좋은 성능을 보였다.
- 다른 포지션에 attention하는 모델의 능력을 향상시켰다. self-attention은 다른 단어들과의 관계들도 보지만, 막상 들여다보면 자기 자신의 단어에 더 많은 영향을 받는 것은 사실이다.
- 여러 개의 “representation subspaces”를 생성할 수 있다. 무슨 뜻이냐면 여러 개의 Attention을 가진 Head는 각각 무작위로 Query, Key, Value가 초기화되므로, 각각 다른 표현 subspace에 embedding을 투영하기 때문이다.
위 두 개는 코드를 짜면서 다시 이해해보기로 한다!
z 벡터가 많아질 수 밖에 없는데?? 각 헤드에서 나온 z벡터를 concatenate 시킨 다음, W⁰ (weight matrix)로 곱해줘서 z차원을 맞춰준다.
Positional Encoding
transformer가 만들고 싶은 모델은 sequence to sequence지만, 위치 정보를 포함하고 있어야 한다. 따라서 positional encoding 기법으로 각 단어의 상대적인 위치 정보를 포함하도록 했다.
기존 Embedding과 같은 차원의 Positional encoding을 만들어 더해줌으로써, time signal을 가진 embedding을 인풋으로 받을 수 있다,
논문에서는 Positional Encoding의 식을 sinusoidal version을 사용했는데, 그 이유는
- 각 포지션의 상대적인 정보를 나타내야함
- 선형 변환을 통해 나타낼 수 있어야함
이 두 가지라고 이해했다.
Positional Encoding을 어떻게 설정해야할까?
[0, 1] 사이로 각 time-step을 할당해야한다.
- 그런데, 얼마나 많은 단어가 올지 모른다는 문제가 있다.
- 다른 아이디어는 각 time-step에 숫자를 1, 2, 3, … 이렇게 선형적으로 할당하는 것이다. 이렇게 되면 문장 길이에 따라 값이 상당히 커질 수도 있다는 문제가 있다.
Positional Encoding이 만족해야하는 조건 정리
- 각 time-step마다 유니크한 값을 가져야한다.
- 어떤 두 개의 time-step 사이의 거리는 서로 다른 길이로 문장 전체에 걸쳐 일관성이 있어야 한다.
- 긴 문장에서도 사용할 수 있도록 일반화되어야 한다. (값이 제한되어야 한다)
- 결정론적 알고리즘이어야 한다.
t : time-step
i : 임베딩 차원
논문에서 제시한 Positional Encoding 방법이다. 여기서 sin, cos을 쓴 이유와, 홀수 짝수 반복해서 벡터 값으로 들어가는 것이 궁금하다.
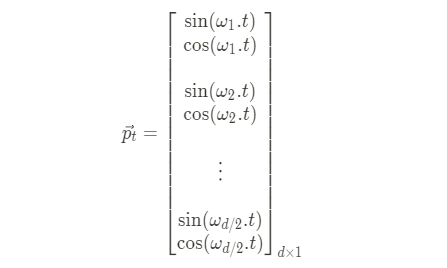
직관적으로 생각했을 때, 4비트로 각 포지션을 표현하면 위와 같이 표현할 수 있다. 하지만 float로 더 풍부하게 나타낼 수 있다는 점을 이용한다.
Relative Positioning
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k, PEpos+k can be represented as a linear function of PEpos.
논문에서는 offset k에 대해서 PE가 선형변환으로 표현될 수 있음을 얘기했다.
왜 선형변호나이 되어야 하냐면, PE가 k에 대해서 [sin, cos, sin, cos, …] 모양을 갖추고, k+ϕ에 대해서도 [sin, cos, sin, cos, …] 을 정의할 수 있어야 각 위치에서 PE 함수를 사용할 수 있기 때문이다.
그렇다면, 위 조건을 만족하는 선형변환 행렬을 구하자.
M 행렬이 2×2 라면, 다음과 같은 선형변호나을 만족하는 M은 어떤 형태일까.

위 식을 풀어서 sin, cos 합 공식을 이용하면 M matrix를 도출할 수 있다. M 행렬은 rotation matrix와 닮았다.(회전 변환) M 행렬을 이용하면 linear function pₜ에 대해서 ϕ만큼 떨어진 것도 표현할 수 있다. sinusoidal을 사용한 또 다른 이유는 인접 time-step 단계 사이의 거리가 대칭이고, 시간에 따라 잘 감소한다는 것이다.
The Residuals
인코더 구조를 자세히 살펴보면, 각 서브 레이어마다 residual connection을 가지고 있다. residual connection 이후, 바로 layer-normalization이 따라온다.
해당 구조를 내부적으로 살펴보면 아래와 같다.
각 단계를 거쳐 Decoder로 들어가는 모습은 아래와 같다.
Decoder
인코더의 가장 상단에 있는 출력은 key와 value 벡터로 바뀐다. 이 key, value 벡터가 decoder의 각 encoder-decoder attention layer에 사용된다.
다음 time-step에서는 decoder의 직전 output을 input으로 다시 받아, Decoder stacks를 거쳐 Linear+Softmax를 한 뒤, 다시 output을 뱉는 과정을 거친다.
디코더에서 주의 깊게 볼 점은, 디코더의 self-attention layer는 해당 output sequence의 전 positions들만 참고하도록 되어 있다. 다음 position들을 softmax step 직전에 masking함으로써 이를 구현했다.
Encoder-Decoder Attention Layer는 Multi-head attention과 같은 동작을 하지만, Query matrix르 ㄹ아래 레이어에서 생성해서, 인코더 스택의 output의 Key, Value matrix를 가져간다.
