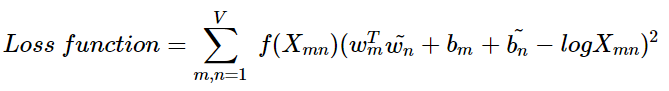2019.06.18
출처 : https://wikidocs.net/book/2155
핵심키워드
- GloVe
- Co-occurrence Matrix
- Co-occurrence Probability
글로브(GloVe)
글로브(Global Vectors for Word Representation, GloVe)는 카운트 기반과 예측 기반을 모두 사용하는 방법론으로 2014년에 미국 스탠포드 대학에서 개발한 단어 임베딩 방법론이다. 앞서 학습하였던 기존의 카운트 기반의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec의 단점을 지적하며 이를 보완한다는 목적으로 나왔고, 실제로도 Word2Vec만큼이나 뛰어난 성능을 보여준다. 현재까지의 연구에 따르면 단정적으로 Word2Vec와 GloVe 중에서 어떤 것이 더 뛰어나다고 말할 수는 없고, 이 두 가지 전부를 사용해보고 성능이 더 좋은 것을 사용하는 것이 바람직하다.
1. 기존 방법론에 대한 비판
잠시 기존의 방법론을 복습해보자. LSA는 TDM이나 TF-IDF 행렬고 같이 각 문서에서의 각 단어의 빈도수를 카운트 한 행렬이라는 전체적인 통계 정보를 입력으로 받아 차원을 축소(Truncated SVD)하여 잠재된 의미를 끌어내는 방법론이었다. 반면, Word2Vec은 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가며 학습하는 예측 기반의 방법론이었다. 서로 다른 방법론을 사용하는 이 두 방법론은 각각 장, 단점이 있다.
LSA는 카운트 기반으로 코퍼스의 전체적인 통계 정보를 고려하기는 하지만, 왕:남자 = 여왕:? (정답은 여자)와 같은 단어 의미의 유추 작업(Analogy task)에는 성능이 떨어진다. Word2Vec은 예측 기반으로 단어 간 유추 작업에는 LSA보다 뛰어나지만, 임베딩 벡터가 윈도우 크기내에서만 주변 단어를 고려하기 때문에 코퍼스의 전체적인 통계 정보를 반영하지 못한다. GloVe는 이러한 기존 방법론들의 각각의 한계를 지적하며, LSA의 메커니즘이었던 카운트 기반의 방법과 Word2Vec의 메커니즘이었던 예측 기반의 방법론 두 가지를 모두 사용한다.
2. 동시 등장 행렬(Co-occurrence Matrix)
단어의 동시 등장 행렬은 행과 열을 전체 단어 집합의 단어들로 구성하고, i 단어의 윈도우 크기(Window Size) 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬을 말한다. 예제를 보면 어렵지 않다. 아래와 같은 텍스트가 있다고 해보자.
ex)
I like deep learning
I like NLP
I enjoy flying
윈도우 크기가 N 일 때는 좌, 우에 존재하는 N개의 단어만 참고하게 된다. 윈도우 크기가 1일 때, 위의 텍스트를 가지고 구성한 동시 등장 행렬은 다음과 같다.

위 행렬은 전치(Transpose)해도 동일한 행렬이 된다는 특징이 있다. 그 이유는 i 단어의 윈도우 크기 내에서 k 단어가 등장한 빈도는 반대로 k 단어의 윈도우 크기 내에서 i 단어가 등장한 빈도와 동일하기 때문이다.
위의 테이블은 스탠포드 대학교의 자연어 처리 강의를 참고하였다(고 한다.)
링크 : http://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture02-wordvecs2.pdf
3. 동시 등장 확률(Co-occurrence Probability)
이제 동시 등장 행렬에 대해서 이해했으니, 동시 등장 확률에 대해서 이해해보자. 아래의 표는 어떤 동시 등장 행렬을 가지고 정리한 동시 등장 확률(Co-occurrence Probability)을 보여준다. 그렇다면, 동시 등장 확률이란 무엇일까?
동시 등장 확률 P(k|i)는 동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트하고, 위에서 배운 동시 등장 행렬에서 중심 단어 i의 행의 모든 값을 더한 값을 분모로하고, i행 k열의 값을 분자로 한 값이라고 볼 수 있다.

위의 표를 통해 알 수 있는 사실은 solid가 등장했을 때, ice가 등장할 확률은 0.00019라은 solid가 등장했을 때 steam이 등장할 확률인 0.00002보다 약 8.9배 크다는 것이다.
그도 그럴 것이 solid는 ‘단단한’이라는 의미를 가졌으니까 ‘증기’라는 의미를 가지는 steam보다는 당연히 ‘얼음’이라는 의미를 가지는 ice라는 단어와 더 자주 등장할 것이다.
수식적으로 다시 정리하면 k가 solid일 떄, P(solid | ice) / P(solid | steam)를 계산한 값은 8.9가 나온다. 이 값은 1보다는 매우 크다. 왜냐면 P(solid | ice) > P(solid | steam) 이기 때문이다.
그런데 k를 solid가 아니라 gas로 바꾸면 얘기는 완전히 달라진다. gas는 ice보다는 steam과 더 자주 등장하므로, P(gas | ice) / P(gas | steam)을 계산한 값은 1보다 훨씬 작은 값인 0.085가 나온다. 반면, k를 water인 경우에는 solid와 steam 두 단어 모두와 동시 등장하는 경우가 많으므로 1에 가까운 값이 나오고, k가 fasion인 경우에는 solid와 steam 두 단어 모두와 등시 등장하는 경우가 적으므로 1에 가까운 값이 나온다. 보기 쉽도록 조금 단순화해서 표현한 표는 다음과 같다.

이제 동시 등장 행렬과 동시 등장 확률의 이해를 바탕으로 손실 함수를 설계해본다.
4. 손실 함수(Loss function)
우선 손실 함수를 설명하기 전에 각 용어를 정리해보자.

GloVe의 아이디어를 한 줄로 요약하면 ‘임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것’이다. 즉, 이를 만족하도록 임베딩 벡터를 만드는 것이 목표이다. 이를 식으로 표현하면 다음과 같다.
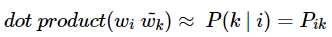
뒤에서 보게 되겠지만, 더 정확히는 GloVe는 아래와 같은 관계를 가지도록 임베딩 벡터를 설계한다.
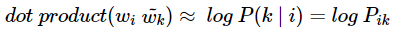
임베딩 벡터들을 만들기 위한 손실 함수를 처음부터 차근차근 설계해본다. 가장 중요한 것은 단어 간의 관계를 잘 표현하는 함수여야 한다는 것이다. 이를 위해 앞서 배운 개념인 Pᵢₖ/Pⱼₖ를 식에 사용한다. GloVe의 연구진들은 벡터 wᵢ, wⱼ, wₖ를 가지고 어떤 함수 F를 수행하면, Pᵢₖ/Pⱼₖ가 나온다는 초기 식으로부터 전개를 시작한다.
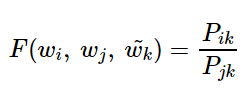
아직 이 함수 F가 어떤 식을 가지고 있는지는 정해진 게 없다. 위의 목적에 맞게 근사할 수 있는 함수식은 무수히 많겠으나 최적의 식에 다가가기 위해서 차근, 차근 디테일을 추가해본다. 함수 F는 두 단어 사이의 동시 등장 확률의 크기 관계 비(ratio) 정보를 벡터 공간에 인코딩하는 것이 목적이다. 이를 위해 GloVe 연구진들은 wᵢ, wⱼ라는 두 벡터의 차이를 함수 F의 입력으로 사용하는 것을 제안한다.
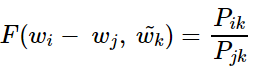
그런데 우변은 스칼라값이고 좌변은 벡터값이다. 이를 성립하기 해주기 위해서 함수 F의 두 입력에 내적(Dot Product)를 수행한다.
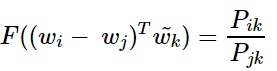
정리하면, 선형 곤간(Linear Space)에서 단어의 의미 관계를 표현하기 위해 뺄셈과 내적을 택했다.
여기서 함수 F가 만족해야할 필수 조건이 있다. 중심 단어 w와 주변 단어 ~w라는 선택 기준은 실제로는 무작위 선택이므로 이 둘의 관계는 자유롭게 교환될 수 있도록 해야한다. 이것이 성립되게 하기 위해서 GloVe 연구진은 함수 F가 실수의 덧셈과 양수의 곱셈에 대해서 준동형(Homomorphism)을 만족하도록 한다. 생소한 용어라서 말이 어려워보이는데, 정리하자면 a와 b에 대해서 함수 F가 F(a+b)가 F(a)F(b)와 같도록 만족시켜야 한다는 의미이다.
식으로 나타내면 아래와 같다.
F(a+b) = F(a)F(b), ∀a, b∈R
이제 이 준동형식을 현재 전개하던 GloVe 식에 적용할 수 있도록 조금씩 바꿔볼 것이다. 전개하던 GloVe 식에 따르면, 함수 F는 결과값으로 스칼라 값(Pᵢₖ / Pⱼₖ)이 나와야 한다. 준동형식에서 a와 b가 각각 벡터값이라면 함수 F의 결과값으로는 스칼라 값이 나올 수 없지만, a와 b가 각각 사실 두 벡터의 내적값이라고 하면 결과값으로 스칼라 값이 나올 수 있다. 그러므로 위의 준동형식을 아래와 같이 바꾼다. 여기서 v₁, v₂, v₃, v₄는 각각 벡터값이다. 아래의 V는 벡터를 의미한다.
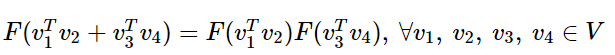
그런데 앞서 작성한 GloVe 식에서는 wᵢ와 wⱼ라는 두 벡터의 차이를 함수 F의 입력으로 받았다. GloVe식에 바로 적용을 위해 준동형 식을 이를 뺼셈에 대한 준동형식으로 변경한다. 그렇게 되면 곱셈도 나눗셈으로 바뀐다.
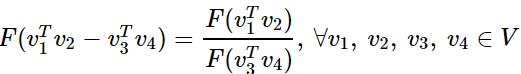
이제 이 준동형 식을 GloVe 식에 적용해본다. 우선, 함수 F의 우변은 다음과 같이 바뀌어야 한다.
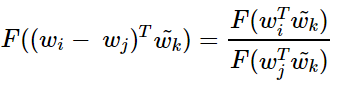
그런데 이전의 식에 따르면 우변은 본래 Pᵢₖ / Pⱼₖ 였으므로, 결과적으로는 다음과 같다.

좌변을 풀어쓰면 다음과 같다.
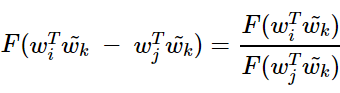
이는 뺄셈에 대한 준동형식의 형태와 정확히 일치한다. 이제 이를 만족하는 함수 F를 찾아야할 때이다. 그리고 이를 정확하게 만족시키는 함수가 있는데 바로 지수 함수(Exponential Function)이다. F를 지수 함수 exp라고 해보자.

위의 두번째 식으로부터 다음과 같은 식을 얻을 수 있다.
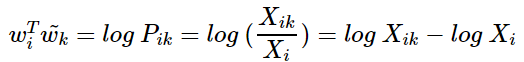
그런데 여기서 상기해야할 것은 앞서 언급했듯이, 사실 wᵢ와 wₖ는 두 값으 위치를 서로 바꾸어도 식이 성립해야 한다. Xᵢₖ의 정의를 생각해보면 Xₖᵢ와도 같다. 그런데 이게 성립되려면 위의 식에서 log Xᵢ항이 걸림돌이 된다. 이 부분만 없다면 이를 성립시킬 수 있다. 그래서 GloVe 연구팀은 이 log Xᵢ 항을 wᵢ에 대한 편향 bᵢ라는 상수항으로 대체하기로 한다. 같은 이유로 wₖ에 대한 편향 bₖ를 추가한다.
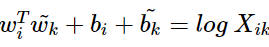
이 식이 손실 함수의 핵심이 되는 식이다. 우변의 값과의 차이를 최소화하는 방향으로 좌변의 4개의 항은 학습을 통해 값이 바뀌는 변수들이 된다. 즉, 손실 함수는 다음과 같이 일반화될 수 있다.
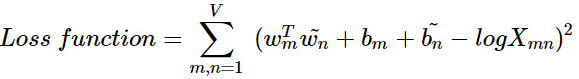
여기서 V는 단어 집합의 크기를 의미한다. 그런데 아직 최적의 손실 함수라기에는 부족하다. GloVe 연구진은 log Xᵢₖ에서 Xᵢₖ 값이 0이 될 수 있음을 지적한다. 대안 중 하나는 log Xᵢₖ항을 log(1+Xᵢₖ)로 변경하는 것이다. 하지만 이렇게 해도 여전히 해결되지 않는 문제가 있다.
바로 동시 등장 행렬 X는 마치 TDM처럼 희소 행렬(Sparse Matrix)일 가능성이 다분하다는 점이다. 동시 등장 행렬 X에는 많은 값이 0이거나, 동시 등장 빈도가 적어서 많은 값이 작은 수치를 가지는 경우가 많다. 앞서 빈도수를 가지고 가중치를 주는 고민을 하는 TF-IDF나 LSA와 같은 몇 가지 방법들을 본 적이 있다. GloVe의 연구진은 동시 등장 행렬에서 동시 등장 빈도의 값 Xᵢₖ이 굉장히 낮은 경우에는 정보에 거의 도움이 되지 않는다고 판단한다. 그래서 이에 대한 가중치를 주는 고민을 하게 되는데 GloVe 연구팀이 선택한 것은 바로 Xᵢₖ의 값에 영향을 받는 가중치 함수(Weighting Function) f(Xᵢₖ)를 손실 함수에 도입하는 것이다.
GloVe에 도입되는 f(Xᵢₖ)의 그래프를 보자.

Xᵢₖ의 값이 작으면 상대적으로 함수의 값은 작도록 하고, 값이 크면 함수의 값은 상대적으로 크도록 한다. 하지만 Xᵢₖ가 지나치게 높다고 해서 지나친 가중치를 주지 않기 위해서 또한 함수의 최대값이 정해져 있다. (최대값은 1) 예를 들어 ‘It is’와 같은 불용어의 동시 등장 빈도수가 높다고 해서 지나친 가중을 받아서는 안된다. 이 함수의 값을 손실 함수에 곱해주면 가중치 역할을 할 수 있다.
이 함수 f(x)의 식은 다음과 같이 정의된다.
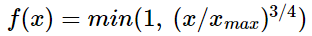
최종적으로 다음과 같은 일반화 된 손실 함수를 얻어낼 수 있다.