2019.06.15
출처 : https://wikidocs.net/book/2155
핵심키워드
- LSTM
장단기 메모리(Long Short-Term Memory, LSTM)
바닐라 아이스크림이 가장 기본적인 맛을 가진 아이스크림인 것처럼, 앞서 배운 RNN을 가장 단순한 형태의 RNN이라고 하여 바닐라 RNN(vanilla RNN)이라고 한다. (케라스에서는 SimpleRNN) 바닐라 RNN 이후 바닐라 RNN의 한계를 극복하기 위한 다양한 RNN의 변형이 나왔다. 이번 챕터에서 배우게 될 LSTM도 그 중 하나이다. 앞으로의 설명에서 LSTM과 비교하여 RNN을 언급하는 것은 전부 바닐라 RNN을 말한다.
1. 바닐라 RNN의 한계

앞 챕터에서 바닐라 RNN은 출력 결과가 이전의 계산 결과에 의존한다는 것을 언급한 바 있다. 하지만, 앞서 배운 RNN은 비교적 짧은 시퀀스(sequence)에 대해서만 효과를 보이는 단점이 있다. 즉, RNN의 시점(time-step)이 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생한다.
위의 그림은 첫번째 입력값인 x₁의 정보량을 짙은 남색으로 표현했을 때, 색이 점차 얕아지는 것으로 시점이 지날수록 x₁의 정보량이 손실되어가는 과정을 표현하였다. 뒤로 갈수록 x₁의 정보량은 손실되고, 시점이 충분히 긴 상황에서는 x₁의 전체 정보에 대한 영향력은 거의 의미가 없을 수도 있다.
어쩌면 가장 중요한 정보가 시점의 앞 쪽에 위치할 수도 있다. RNN으로 만든 언어 모델이 다음 단어를 예측하는 과정을 생각해보자. 예를 들어 “모스크바에 여행을 왔는데 건물도 예쁘고 먹을 것도 맛있었어. 그런데 글쎄 직장 상사한테 전화가 왔어. 어디냐고 묻더라구 그래서 나는 말했지. 저 여행왔는데요. 여기 __” 다음 단어를 예측하기 위해서는 장소 정보가 필요하다. 그런데 장소 정보에 해당되는 단어인 ‘러시아’는 앞에 위치하고 있고, RNN이 충분한 기억력을 가지고 있지 못한다면 다음 단어를 엉뚱하게 예측한다.
이를 장기 의존성 문제(the problem fo Long-Term Dependencies)라고 한다.
2. 바닐라 RNN 내부 열어보기

LSTM에 대해서 이해해보기 전에 바닐라 RNN의 뚜껑을 열어보자. 위의 그림은 바닐라 RNN의 내부 구조를 보여준다. 이 책에서는 RNN 계열의 인공 신경망의 그림에서는 편향 b를 생략한다. 위의 그림에 편향 b를 그린다면 xₜ 옆에 tanh로 향하는 또 하나의 입력선을 그리면 된다.

바닐라 RNN은 xₜ와 h_(t-1)이라는 두 개의 입력이 각각의 가중치와 곱해져서 메모리 셀의 입력이 된다. 그리고 이를 하이퍼볼릭탄젠트 함수의 입력으로 사용하고 이 값은 은닉층의 출력인 은닉 상태가 된다.
3. LSTM(Long Short-Term Memory)

위의 그림은 LSTM의 전체적인 내부의 모습을 보여준다. 전통적인 RNN의 이러한 단점을 보완한 RNN의 일종을 장단기 메모리(Long Short-Term Memory)라고 하며, 줄여서 LSTM이라고 한다. LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정한다. 요약하면 LSTM은 은닉 상태(hidden state)를 계산하는 식이 전통적인 RNN보다 조금 더 복잡해졌으며 셀 상태(cell state)라는 값을 추가했다. 위의 그림에서는 t시점의 셀 상태를 Cₜ로 표현하고 있다. LSTM은 RNN과 비교하여 긴 시퀀스의 입력을 처리하는 데 탁월한 성능을 보인다.

셀 상태는 위의 그림에서 왼쪽에서 오른쪽으로 가는 굵은 선이다. 셀 상태 또한 이전에 배운 은닉 상태처럼 이전 시점의 셀 상태가 다음 시점의 셀 상태를 구하기 위한 입력으로서 사용된다.
은닉 상태값과 셀 상태값을 구하기 위해서 새로 추가 된 3개의 게이트를 사용한다. 각 게이트는 삭제 게이트, 입력 게이트, 출력 게이트라고 부르며 이 3개의 게이트에는 공통적으로 시그모이드 함수가 존재한다. 시그모이드 함수를 지나면 0과 1사이의 값이 나오게 되는데 이 값들을 가지고 게이트를 조절한다. 아래의 내용을 먼저 이해하고 각 게이트에 대해서 알아보자.

(1) 입력 게이트

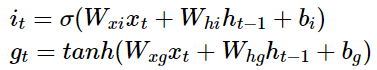
입력 게이트는 현재 정보를 기억하기 위한 게이트이다. 우선 현재 시점 t의 x값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지난다. 이를 iₜ라고 한다. 그리고 같은 입력에 대해서 하이퍼볼릭탄젠트 함수를 지난다. 이를 gₜ라고 한다.
시그모이드 함수를 지나 0과 1 사이의 값고 하이퍼볼릭탄젠트 함수를 지나 -1과 1 사이의 값 두 개가 나오게 된다. 이 두 개의 값을 가지고 이번에 선택도니 기억할 정보의 양을 정하는데, 구체적으로 어떻게 결정하는지는 아래에서 배우게 될 셀 상태 수식을 보면 된다.
(2) 삭제 게이트

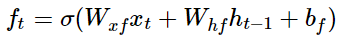
삭제 게이트는 기억을 삭제하기 위한 게이트이다. 현재 시점 t의 x값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지나게 된다. 시그모이드 함수를 지나면 0과 1 사이의 값이 나오게 되는데, 이 값이 곧 삭제 과정을 거친 정보의 양이다. 0에 가까울수록 정보가 많이 삭제된 것이고 1에 가까울수록 정보를 온전히 기억한 것이다. 이를 가지고 셀 상태를 구하게 되는데, 구체적으로는 아래의 셀 상태 수식을 보면 된다.
(3) 셀 상태(장기 상태)

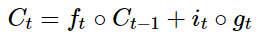
셀 상태 Cₜ를 LSTM에서는 장기 상태라고 부르기도 한다. 그렇다면 셀 상태를 구하는 방법을 알아보자. 삭제 게이트에서 일부 기억을 잃은 상태이다.
입력 게이트에서 구한 iₜ, gₜ 이 두 개의 값에 대해서 원소별 곱(entrywise product)을 진행한다. 다시 말해 같은 크기의 두 행렬이 있을 때 같은 위치의 성분끼리 곱하는 것을 말한다. 여기서는 식으로 ∘로 표현한다. 이것이 이번에 선택된 기억할 값이다.
입력 게이트에서 선택된 기억을 삭제 게이트의 결과값을 더한다. 이 값을 현재 시점 t의 셀 상태라고 하며, 이 값은 다음 t+1 시점의 LSTM 셀로 넘겨진다.
(4) 출력 게이트와 은닉 상태(단기 상태)


출력 게이트는 현재 시점 t의 x값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지난 값이다. 해당 값은 현재 시점 t의 은닉 상태를 결정하는 일에 쓰이게 된다.
은닉 상태를 단기 상태라고 하기도 한다. 은닉 상태는 장기 상태의 값이 하이퍼볼릭탄젠트 함수를 지나 -1과 1사이의 값이다. 해당 값은 출력 게이트의 값과 연산되면서, 값이 걸러지는 효과가 발생한다. 단기 상태의 값은 또한 출력층으로도 향한다.
앞서 배웠던 바닐라(Vanilla RNN)처럼 LSTM으로 언어 모델링을 해보겠다.
4. LSTM으로 문장 생성하기(Sentence Generation using LSTM)
텍스트 생성은 언어 모델링(Language Modelling)에 해당되는 대표적인 예이다. 이번 예제에서는 LSTM을 통해 언어 모델을 설계하고, 입력된 단어로부터 다음 단어를 예측해보도록 하겠다. 여기서 사용할 데이터는 뉴욕 타임즈 기사의 제목이다. 수많은 데이터가 있는데, 그 중에서 ArticlesApril2018.csv 데이터를 사용했다.
이번에는 보다 많은 데이터를 사용했지만, 본질적으로 앞 챕터의 RNN에서 ‘문맥을 고려한 다음 단어 에측하기’ 실습에서 사용했던 코드와 동일한 메커니즘을 가진 코드이다.
파일 다운로드 링크 : https://www.kaggle.com/aashita/nyt-comments
import pandas as pd
df=pd.read_csv('./ArticlesApril2018.csv')
df.head()여기서 우리가 사용할 것은 제목에 해당되는 headline 열이다. headline열만 뽑아서 하나의 리스트로 저장해보도록 하자.
headline = []
headline.extend(list(df.headline.values))
headline[:5]['Former N.F.L. Cheerleaders’ Settlement Offer: $1 and a Meeting With Goodell',
'E.P.A. to Unveil a New Rule. Its Effect: Less Science in Policymaking.',
'The New Noma, Explained',
'Unknown',
'Unknown']
그런데 4번째, 5번째 데이터에 Unkown값이 들어있다. 이는 headline 열 전체에 걸쳐 중간, 중간에 Unkown이라는 데이터가 있기 때문이다. 이는 노이즈 데이터에 해당되므로 Unkown 데이터는 제거해줄 필요가 있다. 제거하기 전에 현재 데이터의 길이가 몇인지 확인해보고 제거 전, 후의 길이를 비교해보자.
len(headline)
1324노이즈 데이터를 제거하기 전 데이터의 길이는 1324이다.
headline = [n for n in headline if n != 'Unknown']len(headline)
1214headline[:5]
['Former N.F.L. Cheerleaders’ Settlement Offer: $1 and a Meeting With Goodell',
'E.P.A. to Unveil a New Rule. Its Effect: Less Science in Policymaking.',
'The New Noma, Explained',
'How a Bag of Texas Dirt Became a Times Tradition',
'Is School a Place for Self-Expression?']
기존에 4번째, 5번째 데이터에서는 Unkown이 나왔었는데 정상적으로 제거가 된 것을 확인하였습니다. 이제 데이터에 대한 전처리를 수행해보겠다. 여기서 수행할 전처리는 노이즈 데이터에 해당되는 구두점 제거와 단어의 개수를 줄이기 위한 소문자화이다.
from string import punctuation
def preprocessing(s):
return ''.join(c for c in s if c not in punctuation).lower()
# 구두점 제거와 동시에 소문자화text = [preprocessing(x) for x in headline]
text[:5]
['former nfl cheerleaders’ settlement offer 1 and a meeting with goodell',
'epa to unveil a new rule its effect less science in policymaking',
'the new noma explained',
'how a bag of texas dirt became a times tradition',
'is school a place for selfexpression']
대부분의 구두점이 제거되었지만 cheerleaders 뒤의 ‘ 구두점이 제거되지 않았는데, 이는 인코딩 문제로 이 또한 제거를 원한다면 아래의 전처리 코드를 수행하면 된다.
from string import punctuation
def repreprocessing(s):
s = s.encode("utf8").decode("ascii",'ignore')
return ''.join(c for c in s if c not in punctuation).lower()
# 구두점 제거와 동시에 소문자화text = [repreprocessing(x) for x in headline]
text[:5]
['former nfl cheerleaders settlement offer 1 and a meeting with goodell',
'epa to unveil a new rule its effect less science in policymaking',
'the new noma explained',
'how a bag of texas dirt became a times tradition',
'is school a place for selfexpression']from keras_preprocessing.text import Tokenizer
t = Tokenizer()
t.fit_on_texts(text)
vocab_size = len(t.word_index)+1
print('단어 집합의 크기 : %d' % vocab_size)
단어 집합의 크기 : 3494sequences = list()
for line in text:
encoded = t.texts_to_sequences([line])[0]
for i in range(1, len(encoded)):
sequence = encoded[:i+1]
sequences.append(sequence)sequences[:5]
[[99, 269],
[99, 269, 371],
[99, 269, 371, 1115],
[99, 269, 371, 1115, 582],
[99, 269, 371, 1115, 582, 52]]max_len = max(len(l) for l in sequences)
print(max_len)
24
가장 긴 데이터의 길이는 24이다. 이제 모든 데이터의 길이를 24로 맞춰준다.
from keras.preprocessing.sequence import pad_sequencesquences
sequences = pad_sequences(sequences, maxlen=max_len, padding='pre')
print(sequences[:3])
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 99 269]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 99 269 371]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 99 269 371 1115]]padding=‘pre’를 설정하면 데이터의 길이가 24보다 짧은 경우에는 앞에 0을 채우는데, 위의 출력 결과는 정상적으로 패딩이 되었음을 보여준다. 이제 X 데이터와 레이블에 해당되는 y 데이터를 분리한다. 분리 방법은 맨 우측에 있는 데이터만 y로 분리한다.
import numpy as np
sequences = np.array(sequences)
X = sequences[:, :-1]
y = sequences[:, -1]print(X[:3])
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 99]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 99 269]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 99 269 371]]
X 데이터를 3개만 출력해보았는데, 맨 우측에 있던 정수 데이터가 사라진 것을 볼 수 있다. 뿐만 아니라, 각 훈련 데이터의 길이도 24에서 23으로 줄었다.
print(y[:3])
[ 269 371 1115]y 데이터를 3개만 출력해봤는데, 기존의 X 데이터에서 맨 우측에 있던 정수들이 별도로 저장된 것을 확인할 수 있다.
from keras.utils import to_categorical
y = to_categorical(y, num_classes=vocab_size)y 데이터에 대한 원-핫 인코딩을 수행한다.
from keras.layers import Embedding, Dense, LSTM
from keras.models import Sequentialmodel = Sequential()
model.add(Embedding(vocab_size, 10, input_length=max_len-1))
# y를 제거하였으므로 x의 길이는 기존 데이터 길이 -1model.add(LSTM(128))
model.add(Dense(vocab_size, activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',
metrics=['accuracy'])
model.fit(X, y, epochs=200, verbose=2)Epoch 1/200
- 8s - loss: 7.6501 - acc: 0.0297
Epoch 2/200
- 7s - loss: 7.1215 - acc: 0.0304
...
중략
...
Epoch 198/200
- 6s - loss: 0.2712 - acc: 0.9161
Epoch 199/200
- 6s - loss: 0.2704 - acc: 0.9168
Epoch 200/200
- 6s - loss: 0.2746 - acc: 0.9163
